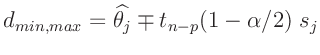Nächste Seite: Bayes Statistik Aufwärts: Das allgemeine lineare Modell Vorherige Seite: Das allgemeine lineare Modell
Gesucht sind die Schätzwerte für
![]() ,
,
![]() und
und
![$ \widehat{\bm{\mathrm{Cov}}[\widehat{\bm{\theta}}]}$](img119.png) , die
den wahren Werten der unbekannten Parameter möglichst nahe kommen. Bei
der Methode der kleinsten Quadrate bestimmt das Minimum der Summe der
quadrierten Abweichung
, die
den wahren Werten der unbekannten Parameter möglichst nahe kommen. Bei
der Methode der kleinsten Quadrate bestimmt das Minimum der Summe der
quadrierten Abweichung
![$\displaystyle \sum_{i=1}^n\sum_{j=1}^n (y_i -\bm{\mathrm{E}}[y_i])p_{i,j} (y_j -\bm{\mathrm{E}}[y_j])$](img122.png) |
|||
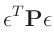 |
|||
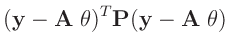 |
|||
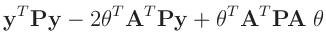 |
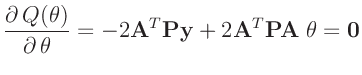
Bisher wurden keine Annahmen über die Verteilung der Messdaten
zu Grunde gelegt. Die optimalen Eigenschaften der Methode der kleinsten
Quadrate folgen einzig aus der Linearität des Modells. Wird für die
Messabweichungen
![]() eine Normalverteilung angenommen, führt die
Maximum-Likelihood-Schätzung von
eine Normalverteilung angenommen, führt die
Maximum-Likelihood-Schätzung von
![]() beziehungsweise die Restringierte Maximum-Likelihood-Schätzung 5von
beziehungsweise die Restringierte Maximum-Likelihood-Schätzung 5von
![]() zu dem gleichen Ergebnis. Unter dieser
Voraussetzung sind sind auch die geschätzten Werte
zu dem gleichen Ergebnis. Unter dieser
Voraussetzung sind sind auch die geschätzten Werte
![]() normalverteilt.
normalverteilt.
Das Konfidenzintervall (Fehlerintervall) eines geschätzten Parameters
![]() wird durch die Wahrscheinlichkeit
wird durch die Wahrscheinlichkeit ![]() bestimmt,
mit der dieser im Intervall
bestimmt,
mit der dieser im Intervall
![]() liegt
liegt
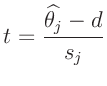
![$\displaystyle s_j = \widehat{\bm{\mathrm{Var}}[\widehat{\theta_j}]}^{1/2}
= \l...
.../2}
= \left(\widehat{\sigma^2}(\bm{A}^T\bm{P} \bm{A})^{-1}_{j,j}\right)^{1/2}
$](img175.png)
Ähnliche Gleichungen kann man in vielen Lehrbüchern zur klassischen
Statistik, z.B in
Nollau (1975) (152ff),
James (2006) (183ff),
Fahrmeir (2009) (124ff),
Martin (2012) (145ff) oder
Wakefield (2013) (214ff)
finden, wobei teilweise anstelle der Gewichtsmatrix ![]() direkt
die inverse Kovarianzmatrix
direkt
die inverse Kovarianzmatrix
![]() benutzt oder das erste
Element des Parametervektors
benutzt oder das erste
Element des Parametervektors
![]() mit
mit ![]() bezeichnet
wird.
bezeichnet
wird.
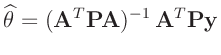
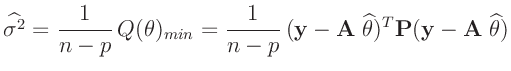
![$\displaystyle \widehat{\bm{\mathrm{Cov}}[\widehat{\bm{\theta}}]} = \widehat{\sigma^2}(\bm{A}^T\bm{P} \bm{A})^{-1}$](img157.png)